Notes on eRPC -- NSDI'19
/本文是NSDI'19 "Datacenter RPCs can be General and Fast" 的学习笔记。
1. Introduction
从传统意义上讲,数据中心中的网络应用,如果想要获得高性能,那么就必须牺牲通用性。
文章中举了这样一个例子:DPDK为网络应用提供了一套底层的接口,它的性能非常好,但是缺失一些通用网络应用要求的功能,比如DPDK只支持 unreliable packet I/O. 而mTCP是一套完整的网络堆栈,它的通用性非常好,但是性能上有比较大的提升空间。
从另外一个角度看,让网络应用获得较高的性能,我们通常采用的办法不是去优化传统的网络协议栈(如Linux内核中TCP协议栈),而是使用新型硬件,如文章中提到的RDMA, Lossless Networks, FPGA等。而这些新型硬件的访问接口与传统的以太网不同,需要专门为这套接口去编写一套软件来利用,这同样也丧失了软件的通用性。
而eRPC完美的解决了这两个问题,同时具备通用性和高性能这两个特性,因为这篇工作也被发表在了NSDI'19上。
2. Background
作者在这部分提到了数据中心网络的两个方面:
Lossless fabrics: Lossless packet delivery是数据链路层的特性,能够防止拥塞导致的丢包。比如以太网的PFC(Priority Flow Control)机制向发送方发送pause frame,来防止发送方发送数据过快导致接收者 buffer overflow. 许多企业在他们的数据中心中部署了PFC,来解决RDMA在丢包情况下性能急剧下降的情况
Switch buffer >> BDP: 随着技术的进步,交换机缓冲区(switch buffer)的大小已经来到了数十MB的量级,远大于数据中心网络的BDP(bandwidth-delay product, 时延带宽积)(约为数十KB);而且交换机的缓冲区是动态的,也就是说,它可以根据端口的负载情况来分配缓冲区,这样就在很大程度上防止缓冲区溢出导致的丢包问题
以上提到的两个方面,我认为作者是想说,在现代数据中心的网络中,丢包发生的概率已经变得非常非常小。
在这个部分,作者还提到了现在已有的技术有着各种方面的局限性和缺陷,此处不再详述,为了解决这些问题,就有了eRPC。
3. eRPC overview
eRPC在不可靠传输层之上实现,这里的不可靠传输层包括UDP和Infiniband's Unreliable Datagram transport. 同时,eRPC需要用户层的NIC驱动,来保证较高的性能。
3.1 eRPC API
从API来看,eRPC的API与其他RPC框架如Accelio非常相似:
服务器端注册request handler function时,会为它们标注唯一的请求类型;客户端在发送RPC时需要指定请求类型,并在RPC完成后执行callback。
- 用户用来发送和接收RPC请求的线程(user threads)都会创建相应的
RPC Endpoint,包含RX和TX queue, event loop和多个session - session代表两个RPC Endpoint的点对点通信,一个user threead可以在不同的session中扮演不同的角色(sender, receiver)
user threads需要周期性运行event loop,event loop承担了eRPC的大部分的职能,如接收发送数据包、拥塞控制和管理等
RPC框架的控制流如下:
客户端:调用
rpc->enqueue_request()将请求入队,在运行event loop时将请求发送出去;在接收到请求后,event loop将接收到的内容拷贝到相应位置,调用callback服务端:event loop每次收到请求后,会调用相应的request handler,然后在任务完成后,调用
enqueue_response(),等待event loop发送响应
3.2 thread model
首先介绍一下文章中提到的两个概念:dispatch threads和worker threads
- dispatch threads: 调度线程,是指负责处理网络I/O的线程。它们负责接收传入的RPC请求,并进行解析、路由和分发给适当的 worker threads 来处理具体的请求
- worker threads:工作线程,是实际执行RPC请求处理的线程。它们接收到来自调度线程的请求,并执行请求所需的操作,例如访问数据库、计算、生成响应等。工作线程处理完请求后,将响应返回给dispatch threads,后者再将响应发送回客户端
现有的RPC框架大概有下面两种thread model:
- RPC请求都由dispatch threads交给worker threads,如RAMCloud。这样会导致线程之间的通信增多,使得request latency提高
- RPC请求都由dispatch threads完成,不会交给worker threads,如FaRM。这样虽然使得request latency降低,但是当调用long request handlers,会导致阻塞,使得tail latency比较高
eRPC结合了两种方式,要求用户在发送请求时指定使用哪一种thread model来执行request handler,这样用户可以根据自身需求来调用eRPC,从而大幅度提高性能。
4. eRPC design
4.1 scalability considerations
eRPC使用packet I/O 发送请求,而不是RDMA write。原因有二:
对于packet I/O,NIC提供了相应的completion queue,通过访问completion queue的头部就可以很方便地检测数据包;而如果使用RDMA write,需要不断的对指定的client buffer进行polling来检测新的数据包,而这样client buffer随着client数量的增加而增加,从而会限制系统的可扩展性
在使用RDMA write进行通信的时候,RDMA会将connection state缓存到NIC中,而NIC的SRAM缓存是非常有限的,因此这同样限制了系统的可扩展性
4.2 challenges in zero-copy transmission
eRPC message buffer layout:

在设计message buffer的时候,原文中提到了这两条原则:
data region必须是连续的,这样的话这块区域可以用作opaque buffer
第一个数据包的header和data是连续的,这样读取small messages只需要一次DMA;如果需要多次DMA的话,那么吞吐率就会显著下降
对于有多个包的message,第2个packet以及之后的packet,它们的header都需要放在msgbuf的最后,否则会违反原则1;这样的话读取第2个packet以及之后的packet时,需要两次DMA,不过这些开销都会在读取large data时被平摊(amortize)(其实也比较好理解,如果是multiple messages的话,data通常也会很多)。
文章中还提到了msgbuf ownership的问题:
No eRPC transmission queue contains a reference to the request msgbuf when the response is processed.
ownership这个问题在没有重传的情况下显得比较trivial,因为在接收到response之前,request就已经退出所有的transmission queue了。但是在存在重传的情况下,就会存在ownership的问题:当client错误地认为丢包发生时,重传request;而server的response已经在重传的request出队之前就已经到达client了,这样就会出现ownership的问题了。
eRPC解决这个问题的思路是这样的:
We choose to make the common case (no retransmission) fast, at the expense of invoking a more-expensive mechanism to handle the rare cases.
我个人觉得这个思路非常地具有启发性,而且事实上大部分的优化工作都应该遵循这样的原则。上面提到了,在数据中心中,丢包已经是小概率事件了,那么在正常情况下的发包收包,便不做处理,一旦出现了重传的情况,那么在将重传请求入队之后,进行flush TX DMA queue的操作,这样会一直阻塞,直到所有queued packets都已经被DMA传输完成了。
4.3 sessions
在eRPC中,每个session可以并发发送请求,来提高网络信道的利用率。eRPC会限制每个session并发发送请求的数量,默认值为8;如果有更多的请求需要session 发送,那么这些请求只能入队。
eRPC 限制未确认的数据包数量,这个值被成为session credit \(C\):
避免因RQ为空导致的丢包
如果发送数据包的速度过快,在短时间内超过了\(|RQ|\),那么会有一些RQ descriptor 溢出,而处理这些的descriptor对应的数据包时,会因为找不到对应descriptor 而丢弃这些数据包
session credit的机制其实实现了端到端的流量控制,这样大大减少了在交换机中排队的数据包的数量,缓解交换机的压力
由此可知,RPC可以参与的session 数量为\(|RQ|/C\). 当\(C\)的值减小时,可参与的session的数量也随之增加,系统的scalability 也随之增加。
- 对于需要低延迟且发送短消息的系统,建议使用较小的\(C\)值
- 对于需要高吞吐率的系统,建议使用较大的\(C\)值
5. Wire Protocol
eRPC实现的wire protocol 比较简单,是client-driven的,也就是说,所有的活动都是由client发起的,而且只有client会维护wire protocol state。
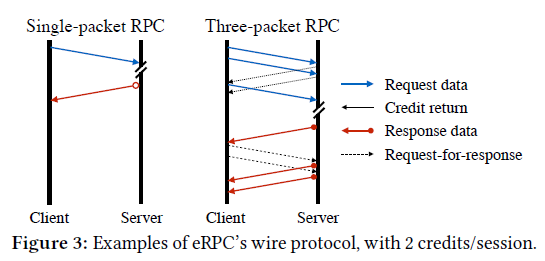
上图中,左边是client向server发送只有一个packet的RPC请求,右边是client向server发送有三个packet的RPC请求,session credit的值为2. 左图理解起来比较简单,来看右图:
client首先向server发送了2个request packet;除了最后一个packet,server每收到一个packet,就会发送credit return packet,来释放前面发送的packet占用的credit。因为协议是client-driven的,server在发送完第1个packet之后,便不能再主动向client发送packet了,之后的数据需要等待client发送request-for-response packet之后,才能继续发送。
比较显然的是,向这样的client-driven protocol相对于其他类型的协议,多发送的数据包如request-for-response这种会提高latency,降低性能,而实际上也确实如此,不过开销并不是非常大,latency只是增加了20%.
关于拥塞控制,eRPC实现了Timely算法,而我个人研究的重点并不是网络方向,此处带过。
6. Microbenchmarks
此处自然有性能数据的对比,如IX和eRPC在相同情况下,单个server core每秒内能够处理的RPC requests的数量为1.5 * 10^6和1 * 10^7.
除了性能方面的数据,比较新颖的是关于generality的 "benchmark"。作者将eRPC迁移到了raft库以及键值存储系统中,发现在提高性能的同时,代码做的改动并不多,这就说明eRPC框架保证了generality。