A Comparative Analysis of Distributed File Systems: GFS, HDFS, and Ceph
/最近一段时间在学习分布式存储系统的经典论文(GFS, HDFS, Ceph)。这篇文章对比了这三个文件系统,总结了它们的共性与特性。
1. Overview
我将从下面几个角度来比较这三个分布式文件系统:
- Architecture
- Metadata Storage
- Data Storage
- Client Operation
- Consistency Model
学习DFS当然不止上面这五个角度,除了这些还有比如每个DFS的特性等,但上面的五个角度是学习分布式文件系统的最基本的五个角度了,所以务必要掌握。
2. Architecture
2.1 GFS
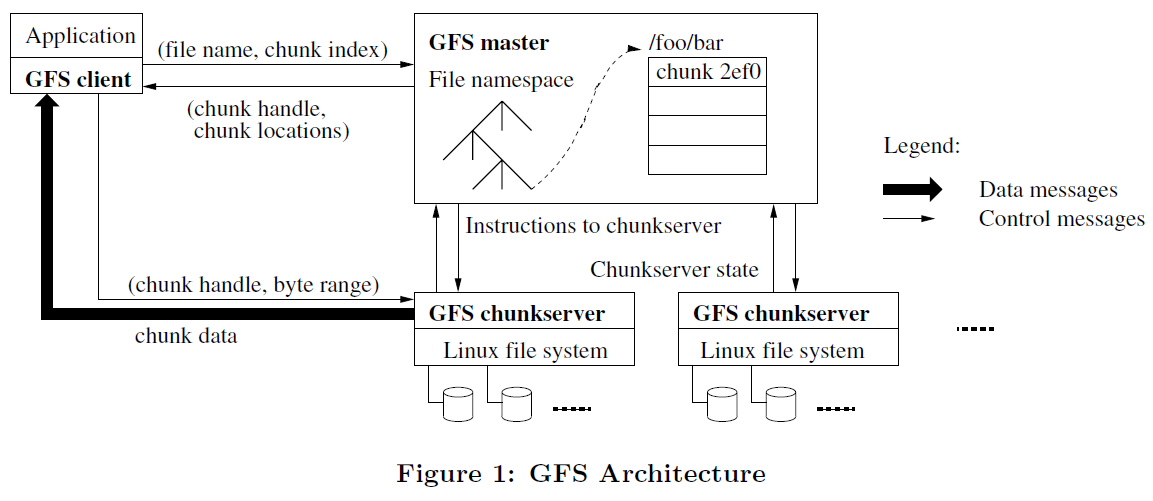
如上图所示,一个GFS集群包括一个Master节点、多个Chunk Server以及多个Client。
关于GFS中的chunk:在GFS中,文件都会被分割成固定大小的chunks(通常是64MB),每一个chunk都以Linux文件的形式,存储在chunk Server中。每一个chunk都有一个对应的64bit的chunk handle(相当于id),读写chunk时,需要指定chunk handle 以及相应的byte range。
Master节点存储GFS的所有metadata,包括namespace, access control information, chunk的位置以及文件到chunk的映射。Master节点同样主导system-wide activities,比如管理chunk lease和chunk migration, 回收orphaned chunks等等。Chunk Server负责存储chunks,Clients作为应用程序的代理,读写集群的数据。
2.2 HDFS
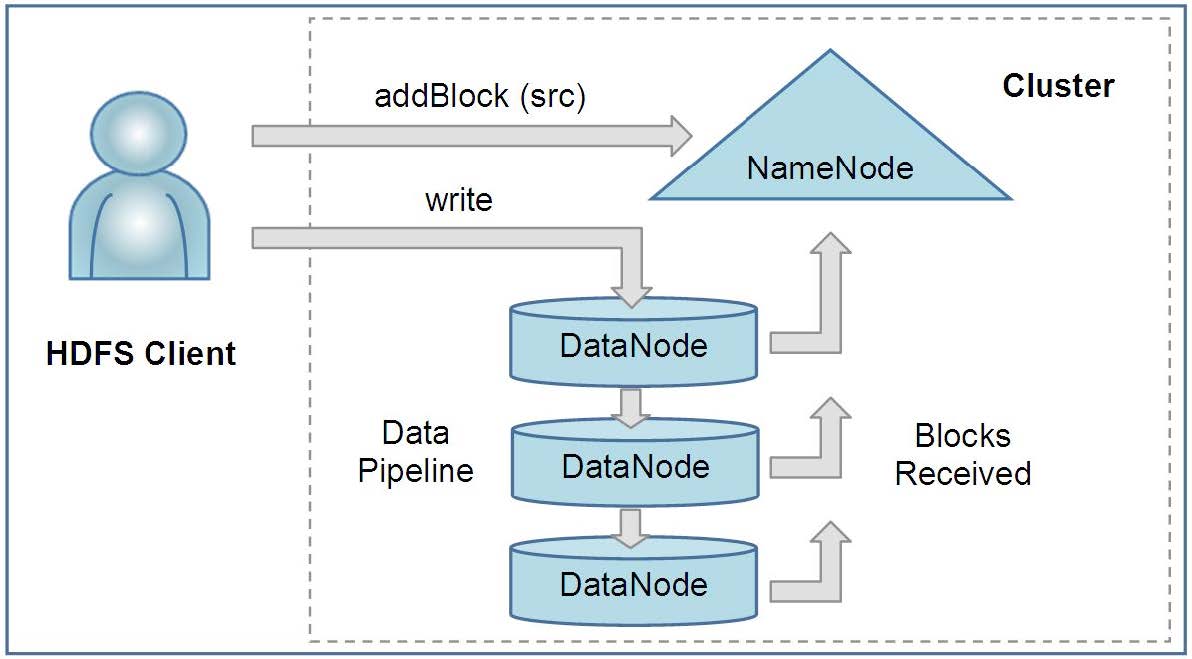
HDFS集群的架构如上图所示,由Name Node, Data Node 和 HDFS Client 三个部分组成。
Name Node 存储文件系统的metadata,如namespace tree,file block所在的Data Node等等。Data Node负责存储block,每一个block对应Data Node之上的两个文件:block data,以及block's metadata(checksum, generation stamp, ...etc). HDFS Clients 作为应用程序的代理,读写集群的数据。
HDFS paper中还提到了Checkpoint Node 和 Backup Node,这些角色都是由Name Node来充当,后面再来介绍。
可以看到,HDFS的架构与GFS的架构非常相似,都是典型的类主-从结构,主节点存储文件系统元数据,从节点负责存储数据。
2.3 Ceph
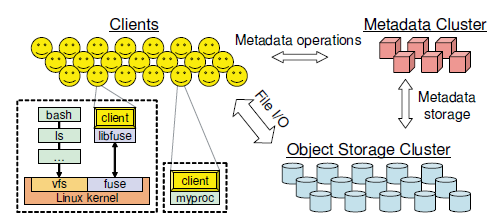
Ceph集群的架构如上图所示,由Clients, MDS Cluster 和 OSD Cluster组成。
Clients向外界暴露了接近POSIX的接口,是外界读写集群数据的代理;Metadata Cluster负责管理namespace(filenames and directories),并存储metadata;OSD Cluster存储数据。
与GFS, Ceph显著不同的是,Ceph的架构并不是主-从结构,而是扁平的结构,MDS Cluster与GFS 中的Master并不相同,且在MDS Cluster和OSD Cluster内部,也没有类似主节点的结构。
3. Metadata Storage
| GFS | HDFS | Ceph | |
|---|---|---|---|
| update content persistency | operation log | journal | journal |
| checkpoint mechanism | yes | Checkpoint Node | not mentioned |
| update content backup | multi machines | Backup Node | OSD cluster |
GFS, HDFS, Ceph为了较高的响应速度,都选择将metadata 存放在内存中(in-memory cache)。当客户端请求文件的metadata时,只需要从内存中查找就可以。但数据存放在内存是十分不安全的,机器掉电之后都会导致内存数据丢失,因此必须有方法来保证metadata persistence.
三者采用的应该都是 journal/log + checkpoint 的机制 (ceph paper 中未提到类似checkpoint的减小journal大小的机制,但猜测具体实现中应该会存在):
- 每次更新metadata时,将更新内容写入持久化存储(gfs: operation log; hdfs, ceph: journal),在机器掉电后重启时,replay journal就可以恢复掉电前的内存状态
- 文件系统可能会运行很长时间,如果不做处理,journal会变得非常大,占满整个磁盘,并且replay耗时较长。所以每隔一段时间,就要做checkpoint:读取上一次的checkpoint,将journal中的更新全部应用到内存中,得到新的内存状态后,将新的内存状态做checkpoint,写入磁盘,同时清空journal
这样的机制被广泛使用,可以在redis AOF+RDB 以及raft log+snapshot 中看见类似的实现。
机制大概如此,但是还是存在着问题,如果log 丢失了怎么办,比如硬盘损坏?
三个文件系统都有着自己不同的方法实现这套机制,以及解决上述提出的新问题:
- GFS 中master节点有多份operation log,存放在不同的主机上。每次将更新写入operation log,只有在更新成功写入所有主机的持久介质之后才能返回
之前提到了HDFS中的CheckPoint Node和Backup Node。CheckPoint Node做的事情就是刚才提到的第2点,从NameNode中获取旧的checkpoint和journal,二者结合之后生成新的checkpoint,并清空journal,并将checkpoint返回给NameNode;Backup Node顾名思义,就是做备份的Node,当NameNode向journal写入更新时,会将同样的更新发送给Backup Node;当NameNode Fail(各种形式上的)时,Backup Node就可以挺身而出
Ceph 应该会在OSD cluster中保存每一个MDS的journal 备份(MDS journal是存放在MDS主机上的)。当更新写入journal之后,很快更新就会写入存放在OSD 的备份
值得注意的是,为了提高效率,文件系统通常会将更新按照批次(batch)写入持久化截止,来提高效率,否则每次写入只写入很小的内容会浪费I/O资源。
4. Data Storage
| GFS | HDFS | Ceph | |
|---|---|---|---|
| Striping | fixed size(64 MB) | fixed size(128MB) | striping strategy(no details) |
| Snapshot | copy-on-write, duplicate metadata | duplicate hard links | not implemented |
| Placement | not mentioned | Cluster Topology | OSD cluster map |
4.1 GFS
前面提到了,在GFS中,文件被分成固定大小的chunks,每一个chunk的大小为64MB。Chunk Servers以Linux文件的形式存储chunk,每一个chunk都对应着一个唯一的chunk handle(id)。对chunk进行读写操作时,只需要指定chunk handle与byte range即可。每一个chunk都会有多个副本,GFS的默认策略是为3个副本,可以根据实际需求来改动replication level。
4.1.1 Snapshot
既然是分布式存储系统,那么就肯定会有对应的Snapshot机制来保证数据的安全性。GFS使用的是与AFS类似的copy-on-write 机制来实现snapshot。
当master节点收到snapshot请求时,首先要做的是revoke any outstanding leases,来阻塞来自客户端的写操作;之后duplicating the metadata for the source file or directory tree(原句),新创建的snapshot files 会指向与原文件相同的chunks。当写请求要写被snapshot过的chunk时,会创建一个新的chunk及其对应的chunk handle,也就是所谓的copy-on-write机制。
原文中的这句话duplicating the metadata for the source file or directory tree 有点难理解,其实这比较类似于CMU 15445 Project 0中的copy-on-write Trie,具体实现的话应该和HDFS的实现差不太多,下面会讲到。
4.2 HDFS
和GFS类似,在HDFS中,每一个文件会被分割成固定大小的block(128MB),在Data Nodes上,每一个block对应两个文件:block data和block metadata(checksums, ...etc). NameNode会存储 mapping of file blocks to Data Nodes。
4.2.1 Snapshot
HDFS也有对应的Snapshot机制,摘录原文如下:
Instead each DataNode creates a copy of the storage directory and hard links existing block files into it. When the DataNode removes a block it removes only the hard link, and block modifications during appends use the copy-on-write technique.
原文中说的hard links,应该与GFS中提到的snapshot files非常类似,但目前尚未求证。
4.2.2 Placement Policy
为了保证数据的reliability与读写文件时的性能,HDFS提出了自己的replica placement policy:
The default HDFS replica placement policy can be summarized as follows: 1. No Datanode contains more than one replica of any block. 2. No rack contains more than two replicas of the same block, provided there are sufficient racks on the cluster.
HDFS Paper中提到的一个例子中,当创建一个新的block时,第一个副本首先会存放在writer 所在的DataNode,第二个、第三个副本就会分配到不同的rack中。
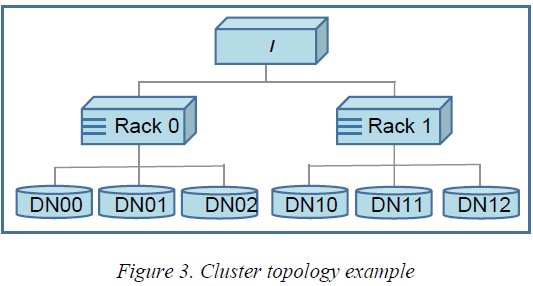
为了估计节点之间网络带宽(目的是衡量节点通信时的效率),HDFS还提出了基于树状拓扑的办法,如上图所示。节点之间的距离就是两个节点到到根节点的距离之和,距离越短,就意味着这两个节点通信时的带宽就会越大,通信效率就越高。正因此,HDFS Client在读取数据的过程中,会优先选择从距离自己最近的Data Node读取数据。
4.3 Ceph
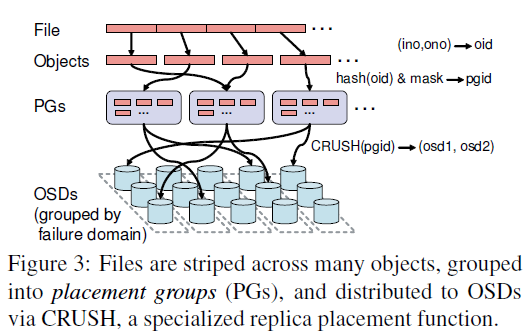
Ceph存储文件数据的方式与GFS, HDFS相差比较大。在GFS, HDFS中,文件被分成固定大小的块(chunk, block),而在Ceph中,文件数据被条带化(striped)之后,通过一个简单的hash函数(bit mask)形成PGs(Placement Groups)后,通过CRUSH算法存储到OSD Cluster中。关于striping strategy, 论文中没有给出具体细节。
Ceph这样去中心化存储文件数据的好处是,不需要再为每一个文件维护 per-file block list,也不需要设定类似Master节点或者Name Node这样的节点。Client只要从MDS Cluster中获得文件的inode id,就可以通过CRUSH算法直接算出文件stripe的位置。
Ceph Paper中尚未提到实现和GFS, HDFS类似的Snapshot机制,在论文的结尾提到了之后会实现这样的功能。Ceph也有自己的Placement Policy,该Policy依据的是OSD cluster map,和前面提到的HDFS的树状拓扑结构比较类似,Replica的放置策略与HDFS也比较类似:
For example, one might replicate each PG on three OSDs, all situated in the same row (to limit inter-row replication traffic) but separated into different cabinets (to minimize exposure to a power circuit or edge switch failure)
5. Client Operation
5.1 GFS
Read:
Client用固定的块大小将应用程序指定的文件名和byte range转换为文件中的chunk index。接着,Client将文件名和 byte offset发送给Master,Master返回相应的chunk handle,以及replica所在的位置(副本处于哪一台chunk server上)。Client会缓存来自Master的这些信息,并根据这些信息找到离自己最近的chunk server,向其发送请求来读取chunk 内容。
Write:
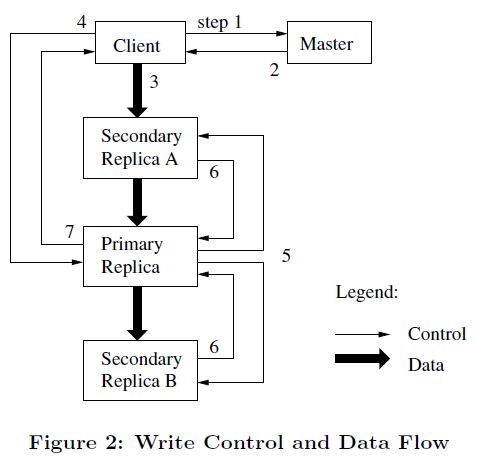
首先解释一下GFS中lease的概念:
We use leases to maintain a consistent mutation order across replicas. The master grants a chunk lease to one of the replicas,which we call the primary. The primary picks a serial order for all mutations to the chunk.
有了lease后,自然会出现续期、到期等问题,此处不再赘述,有兴趣可以到原文中查阅相关细节。
GFS的文件写入数据的流程大致如下:
Client 询问 Master 哪台chunk server 持有该分块的current lease,以及其他副本的位置
Master 返回 1中 Client 请求的信息
- Client 将要写入的数据推送给该 chunk 的副本 (linear pipeline)
- 一旦所有副本都确认收到数据,客户端就会向 primary 发送写请求
- primary 会向所有的其他副本转发写请求
- 所有其他副本向 primary 确认写入请求已经完成
primary 响应客户端,表示写入已经成功完成,否则会返回错误
5.2 HDFS
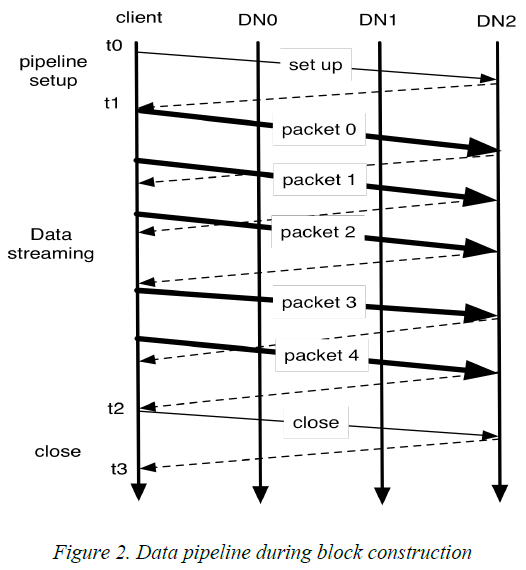
HDFS的读写过程与GFS几乎完全相同,此处不再赘述。下图是对5.1中提到的linear pipeline的可视化:
5.3 Ceph
无论读还是写,Client 都首先要向MDS cluster 请求文件名对应的 file inode,包含inode number, file owner, ...etc, 另外还有条带化文件数据使用的striping strategy。有了这些之后,无论我们需要文件的哪一部分(byte range),都可以根据来自MDS cluster的striping strategy和CRUSH算法算出副本所在的OSD,从OSD cluster读写数据。
关于读写数据的细节,Ceph Paper中没有详细的论述,此处有待补充。
6. Consistency Model
6.1 GFS
GFS的Consistency Model主要是论文中的这个表格:
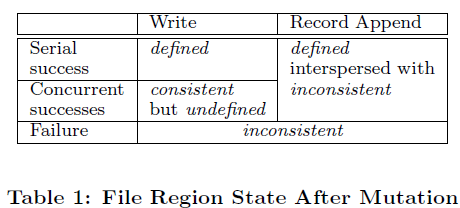
GFS用两个关键词来描述file region: consistent, defined
consistent: all clients will always see the same data, regardless of which replicas they read from
defined: consistent and clients will see what the mutation writes in its entirety
下面用三张图描述表中提到的三种状态:defined, consistent but undefined, defined interspersed with inconsistent
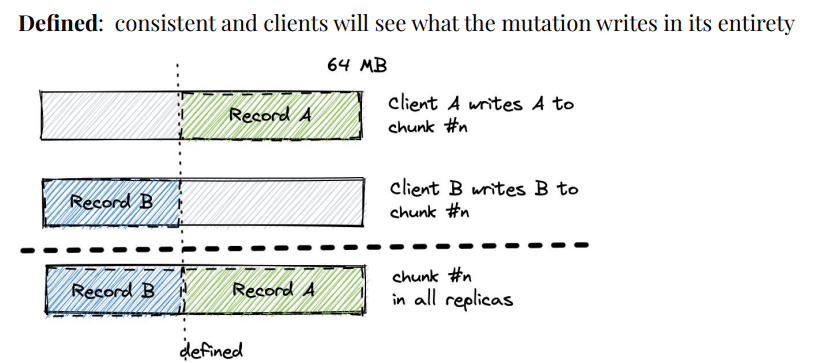
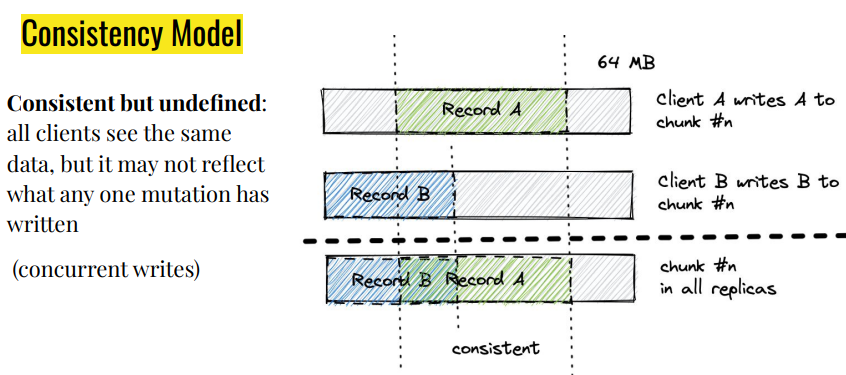

其中我个人觉得理解难度比较大的是defined interspersed with inconsistent这种情况,在有了图示之后,就能够看的比较明白了。当Atomic Append 操作失败后,Client会重试,这样会导致duplicate和padding的出现。出现这种情况也是由于GFS Consistency Model相对Relax。解决这个问题的办法在GFS Paper中也提出了,可以使用Checksum和Unique ID来解决,GFS也提供了相应的库,让应用程序非常简单地实现这两种机制。
在GFS Consistency Model中,GFS保证在一系列successful mutations之后,mutated file region一定是defined而且包含最后一次写入的数据。GFS通过两种机制来保证这一条件:
- applying mutations to a chunk in the same order on all its replicas
- using chunk version number to detect any replica that has become stale
6.2 Ceph
Ceph实现了POSIX语义,而POSIX语义要求reads reflect any data previously written, and that writes are atomic。所以当一个文件被多个Client打开时,the MDS will revoke any previously issued read caching and write buffering capabilities, forcing client I/O for that file to be synchronous. 也就是说禁用除当前正在读写的Client以外的所有Clients的缓存功能,来使得I/O变为同步(synchronous)。
Synchronous I/O 显然会显著影响性能,为了解决性能问题,Ceph扩展了POSIX接口,比如为open操作添加了新的flag O_LAZY,让应用程序显示降低对共享文件读写一致性的要求。